
こんにちは!MIYAKAWA AI の宮川です。
たまにはブロガーっぽい語り口でいこうと思います(笑)
最近、LLM(大規模言語モデル)の話題をよく耳にしますよね。ChatGPTをはじめ、様々なAIが登場し、その可能性にワクワクしています。LLMのファインチューニングの学習中なので今回の機会と技術を利用して、しばらくお休みしていた私の「ミヤカワ映画ブログ https://miyakawa.me/ の再開に活かせないかと考えました。
目標は、LLMをファインチューニングして、私の文章のクセを学習させ、映画ブログの記事作成をサポートしてくれるアシスタントを作ること!
そのためには、まず「私の文章データ」をLLMが学習できる形式、つまりデータセットにする必要があります。幸い、過去にWordPressで書いた映画レビュー記事が100件以上あります。これを活用しない手はありません!
今回は、このWordPressの過去記事を使って、LLMファインチューニング用のデータセットを作成するプロセスを、試行錯誤や苦労した点も含めて赤裸々に(?)記録していこうと思います。同じように挑戦したい方の参考になれば嬉しいです。
データセットの理想形:まずはゴール設定
LLMのファインチューニングでは、多くの場合、特定のフォーマットでデータを用意する必要があります。今回は、各記事の本文を抽出して、以下のような**JSON Lines (JSONL)**形式を目指すことにしました。1行に1つのJSONオブジェクトが記述される形式です。
#JSON例
{"text": "ブログ記事1の本文全体..."}
{"text": "ブログ記事2の本文全体..."}
{"text": "ブログ記事3の本文全体..."}(補足:最終的に作成したPythonスクリプトでは、後々の管理や分析も考えて、記事IDやタイトルなども含めることにしました。詳細は後述します。)
データ抽出方法の検討:最初のつまづき
さて、どうやってWordPressから記事データを抜き出すか。
Webサイトから情報を自動収集するスクレイピングという手もありますが、今回は自分で管理しているWordPressサイト。データベースに直接アクセスする方が確実で効率的だろうと考えました。
最初の計画: Pythonでサクッと! サーバーにSSH接続して、mysql-connector-pythonというライブラリを使って、Pythonスクリプトでデータベースから直接データを抽出しよう!…と考えました。VPS(仮想専用サーバ)など、自由にソフトウェアをインストールできる環境ならこれが一番スマートかもしれません。
実行しようとしたコマンド (参考)
#Bash
pip install mysql-connector-pythonしかし、ここで問題発生!
私のブログが動いているサーバーは共用サーバーでした。そのため、管理者権限がなく、新しいPythonライブラリを自由にインストールできなかったのです…。残念!これは共用サーバーを利用している場合に、よくある制限かもしれませんね。
教訓: 実行環境(サーバーの種類や権限)によって、使える技術やアプローチが変わってくる。事前に確認が大事!
補足:いま見て頂いている MIYAKAWA AIブログ https://miyakawai.com/ はVPSサーバを借りて、私がサーバ構築と管理を全ておこなっています。
代替案:phpMyAdminとSQLでデータ抽出
Pythonで直接アクセスできないなら、別の方法を考えなければなりません。幸い、共用サーバーでもphpMyAdmin(WebブラウザからMySQLデータベースを管理できるツール)は利用可能でした。
そこで、以下のステップで進めることにしました。
- phpMyAdminでSQLを実行し、必要な記事データを抽出する。
- 抽出したデータをCSVファイルとしてダウンロードする。
- ローカル環境(自分のPC)でPythonを使い、CSVファイルを読み込んでデータクレンジング(不要な情報の除去)とJSONL形式への変換を行う。
ステップ1:phpMyAdminで「映画」カテゴリIDを特定
まずは、たくさんある記事の中から「映画」カテゴリの記事だけを絞り込む必要があります。そのために、「映画」カテゴリに割り当てられている内部的なID (term_taxonomy_id) を調べます。
phpMyAdminにログインし、WordPressのデータベースを選択。SQL実行タブで以下のクエリを実行しました。
#SQL
SELECT t.term_id, tt.term_taxonomy_id
FROM wp_terms AS t
INNER JOIN wp_term_taxonomy AS tt ON t.term_id = tt.term_id
WHERE tt.taxonomy = 'category' AND t.name = '映画'; -- '映画'の部分はご自身のカテゴリ名に合わせてくださいこのクエリは、wp_terms(カテゴリ名などが格納されているテーブル)とwp_term_taxonomy(カテゴリと投稿タイプの関連付けなどが格納されているテーブル)を結合し、「カテゴリ」として登録されていて、名前が「映画」であるもののIDを検索します。
実行結果に表示された term_taxonomy_id の値をメモしておきます。(ここでは仮に 7 とします)
ステップ2:phpMyAdminで記事データをCSVエクスポート
次に、特定したカテゴリIDを使って、該当する記事の情報を抽出します。今回は、記事のID、タイトル、本文、投稿日時を取得することにしました。カテゴリ名も後で分かるように固定値で追加しておきます。
phpMyAdminの左側メニューでWordPressの投稿データが格納されているテーブル(通常は wp_posts)を選択してから、以下のSQLを実行します。
注意: クエリ内の tr.term_taxonomy_id = 7 の 7 は、ステップ1で調べた実際の term_taxonomy_id に置き換えてください!
#SQL
SELECT
p.ID,
p.post_title,
p.post_content,
p.post_date,
'映画' AS category -- カテゴリ名を固定値として追加 (必要に応じて変更)
FROM
wp_posts AS p
INNER JOIN
wp_term_relationships AS tr ON p.ID = tr.object_id
WHERE
p.post_type = 'post' -- 投稿タイプが 'post' (通常の記事)
AND p.post_status = 'publish' -- 公開済みの記事
AND tr.term_taxonomy_id = 7; -- ★ここに先ほど調べた「映画」カテゴリのIDを入れる!このクエリは、wp_posts(投稿テーブル)と wp_term_relationships(投稿とカテゴリ/タグの関連付けテーブル)を結合し、投稿タイプが’post’で、公開済み(publish)、かつ指定したカテゴリID(term_taxonomy_id)に属する記事の情報を抽出します。
SQLを実行すると結果が表示されるので、ページ下部にある「エクスポート」機能を使って、CSV形式でデータをダウンロードします。ファイル名は分かりやすく「downloaded_data.csv」としました。
データクレンジング:Pythonで不要な情報を取り除く
さて、CSVファイルが手に入りましたが、このままでは使えません。WordPressの post_content には、文章だけでなく、HTMLタグ(<p>, <a>, <img>など)や、WordPress特有のショートコード( や [blogcard] など)、不要な改行やスペースがたくさん含まれています。
これらをLLMの学習データとして使う前に、**きれいに掃除(クレンジング)**する必要があります。ここでようやくPythonの出番です!
ローカル環境で、以下のPythonスクリプトを作成しました。
使用ライブラリ
csv: CSVファイルの読み書きjson: JSON形式の処理BeautifulSoup(frombs4): HTMLタグの除去 (pip install beautifulsoup4 lxmlでインストール)os: ファイルシステムの操作(今回は未使用ですが、よく使うので入れておく)re: 正規表現(ショートコードなどの複雑なパターン除去)
Pythonスクリプト (data_cleaner.py など)
#Python
import csv
import json
from bs4 import BeautifulSoup
import os
import re
# --- 設定 ---
CSV_FILENAME = 'downloaded_data.csv' # ダウンロードしたCSVファイル名
OUTPUT_FILENAME = 'wordpress_posts_映画_processed.jsonl' # 出力するJSONLファイル名
# --- 設定ここまで ---
all_posts_data = []
success = False # 処理成功フラグ
try:
# CSVファイルをUTF-8で開く
with open(CSV_FILENAME, 'r', encoding='utf-8', newline='') as csvfile:
# ヘッダー行をキーとする辞書として読み込む
reader = csv.DictReader(csvfile)
print(f"CSVファイルを読み込み中: {CSV_FILENAME}")
# 念のためヘッダーを確認
print(f"CSVヘッダー: {reader.fieldnames}")
# --- 正規表現を事前にコンパイル (効率化のため) ---
# [caption]ショートコードを除去 (DOTALLで複数行、IGNORECASEで大文字小文字無視)
caption_re = re.compile(r'\[caption.*?\[/caption\]', flags=re.DOTALL | re.IGNORECASE)
# [blogcard]ショートコードを除去
blogcard_re = re.compile(r'\[blogcard\s+url=.*?\]', flags=re.IGNORECASE)
# 3つ以上連続する改行を2つにまとめる
newline_re = re.compile(r'\n{3,}')
# 連続する半角スペースを1つにまとめる
space_re = re.compile(r' +')
# --- コンパイルここまで ---
# 1行ずつ (1記事ずつ) 処理
for i, row in enumerate(reader):
# 'post_content' 列を取得 (存在しない場合や空の場合は空文字)
content = row.get('post_content', '')
if not content: # 本文が空ならスキップ
print(f"行 {i+1}: ID {row.get('ID', 'N/A')} の本文が空のためスキップします。")
continue
# --- データクリーニング開始 ---
# 1. HTMLタグを除去 (BeautifulSoupを使用)
# 'lxml'パーサーを使用。なければ'html.parser'でも可
# separator='\n' でタグを改行に置換、strip=True で前後の空白を除去
soup = BeautifulSoup(content, 'lxml')
cleaned_text = soup.get_text(separator='\n', strip=True)
# 2. キャプションショートコードを除去
cleaned_text = caption_re.sub('', cleaned_text)
# 3. ブログカードショートコードを除去
cleaned_text = blogcard_re.sub('', cleaned_text)
# 4. 改行/空白の正規化
cleaned_text = cleaned_text.replace('\r\n', '\n') # Windows形式の改行をUnix形式に統一
cleaned_text = newline_re.sub('\n\n', cleaned_text) # 連続改行を2つに
cleaned_text = cleaned_text.replace(' ', ' ') # 全角スペースを半角スペースに
cleaned_text = space_re.sub(' ', cleaned_text) # 連続する半角スペースを1つに
# --- クリーニングここまで ---
# 最終的なテキストの前後の空白を除去
final_text = cleaned_text.strip()
# クリーニング後のテキストが空でなければデータをリストに追加
if final_text:
post_data = {
# IDは数値として格納 (エラー時は0)
"id": int(row.get('ID', 0)),
# タイトル (存在しない場合は空文字)
"title": row.get('post_title', ''),
# クリーニングされた本文
"text": final_text,
# カテゴリ (CSVから取得、なければ'映画')
"category": row.get('category', '映画'),
# 投稿日時 (存在しない場合はNone)
"post_date": row.get('post_date', None)
}
all_posts_data.append(post_data)
else:
print(f"行 {i+1}: ID {row.get('ID', 'N/A')} はクリーニング後に本文が空になったためスキップします。")
print(f"CSVから {len(all_posts_data)} 件の有効な投稿を処理しました。")
success = True # CSV処理成功
except FileNotFoundError:
print(f"エラー: CSVファイルが見つかりません: {CSV_FILENAME}")
except ImportError:
print("エラー: 必要なライブラリ (BeautifulSoup4, lxml) がインストールされていません。")
print("pip install beautifulsoup4 lxml を実行してください。")
except Exception as e:
print(f"CSV処理中に予期せぬエラーが発生しました: {e}")
# --- CSV処理が成功し、データが存在する場合のみファイル書き出し ---
if success and all_posts_data:
try:
# JSONL形式でファイルに書き出し (1行1JSON)
with open(OUTPUT_FILENAME, 'w', encoding='utf-8') as f:
for item in all_posts_data:
# ensure_ascii=False で日本語をそのまま出力
f.write(json.dumps(item, ensure_ascii=False) + '\n')
print(f"{len(all_posts_data)} 件の投稿を {OUTPUT_FILENAME} に正常に書き出しました。")
except IOError as e:
print(f"ファイル書き込み中にエラーが発生しました ({OUTPUT_FILENAME}): {e}")
except Exception as e:
print(f"ファイル書き込み中に予期せぬエラーが発生しました: {e}")
elif success:
print("有効なデータがなかったため、ファイルは書き出されませんでした。")
else:
print("CSV処理に失敗したため、ファイル書き出しは行われませんでした。")
print("処理完了。")スクリプトのポイント
- HTML除去:
BeautifulSoupライブラリが非常に強力です。get_text()メソッドで簡単にテキスト部分だけを抽出できます。 - ショートコード除去:
re.sub()を使って正規表現で特定のパターン(など)に一致する部分を空文字に置換しています。除去したいショートコードの種類に応じて正規表現を追加・修正する必要があります。 - 空白・改行の正規化: 連続する改行やスペース、全角スペースなどを統一的な形式に整えます。これも地味ですが、LLMの学習品質に関わる重要な処理です。
- エラー処理:
try...exceptでファイルが見つからない場合や、処理中の予期せぬエラーを捕捉するようにしています。 - 出力形式: 最終的に
all_posts_dataリストに格納された記事データ(辞書形式)を、json.dumps()でJSON文字列に変換し、1行ずつファイル (OUTPUT_FILENAME) に書き出すことで JSON Lines (JSONL) 形式のファイルを作成しています。ensure_ascii=Falseを指定することで、日本語が\uXXXXのようにエスケープされず、そのまま出力されます。
このスクリプトを、ダウンロードしたCSVファイル (downloaded_data.csv) と同じディレクトリに置いて実行すると、wordpress_posts_映画_processed.jsonl という名前で、クリーニング済みのデータセットファイルが生成されます。
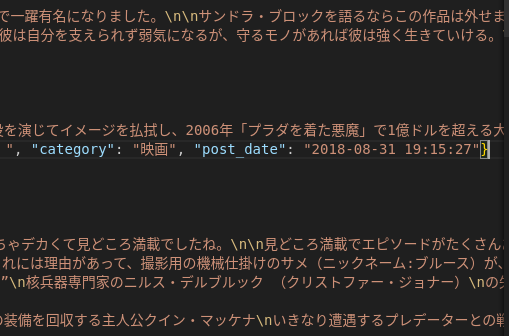
生成されるJSONLファイルの中身(例)
先頭はid, title, textで始まり、後半はcategory, post_dateで終わります。

まとめと今後の展望
ということで、今回はWordPressブログの記事データを抽出し、LLMファインチューニング用のデータセット(JSONL形式)を作成するまでのプロセスをご紹介しました。
当初の計画通りにはいかない部分(Pythonでの直接DBアクセス不可)もありましたが、phpMyAdminとSQL、そしてローカルでのPythonスクリプトを組み合わせることで、目的を達成できました。
今回の学び・注意点
- 環境の制約を考慮する: サーバー環境(共用かVPSかなど)によって使えるツールが異なる。
- SQLは便利: データベースから特定の条件でデータを抽出するにはやはりSQLが強力。
- データクレンジングは必須: 生データには不要な情報(HTML、ショートコード、余分な空白)が多い。
BeautifulSoupや正規表現(re)が役立つ。 - 試行錯誤はつきもの: 最初から完璧な方法はなく、問題にぶつかったら代替案を探す柔軟性が大事。
- JSON Lines形式: LLMの学習データとして一般的な形式の一つ。扱いやすい。
これでようやく、LLMファインチューニングのスタートラインに立てました! 次はこのデータセットを使って、実際にLLMモデル(どのモデルを使うかはまだ検討中)のファインチューニングに挑戦してみようと思います。
その過程も、またブログで報告できればと思いますので、お楽しみに!
※この記事の作成には、一部生成AI(Google Geminiなど)を利用しています。
ピンバック: Google ColabでLLMファインチューニング【実践】:WordPressデータからブログAIアシスタント作成 | MIYAKAWA AI