
今日は、せっかく構築したLlama.cppを使って、ChatBotやRAGを学ぶ準備として、LLMモデルの動作テストを兼ねて環境を再確認しました。
Llamaの各種モデルを動かすためのLlama.cpp環境は事前に構築してありますが、今回は日本語チャットができる状態までの準備を行いました。
準備1: 日本語モデルの選定
日本語対応のLLMモデルを探すために、Hugging Faceを利用しました。最終的に見つけたのは Llama-3-ELYZA-JP-8B-GGUF です。
このモデルは、日本語に特化してファインチューニングされており、日本語の自然な会話をサポートしてくれることが期待できます。
準備2: モデルファイルの配置
ダウンロードした Llama-3-ELYZA-JP-8B-q4_k_m.gguf を Llama.cpp/models フォルダに移動しました。
これで、Llama.cppがモデルを認識できる状態になります。
準備3: llama-serverの起動
次に、llama-server を起動してチャット環境を整えました。
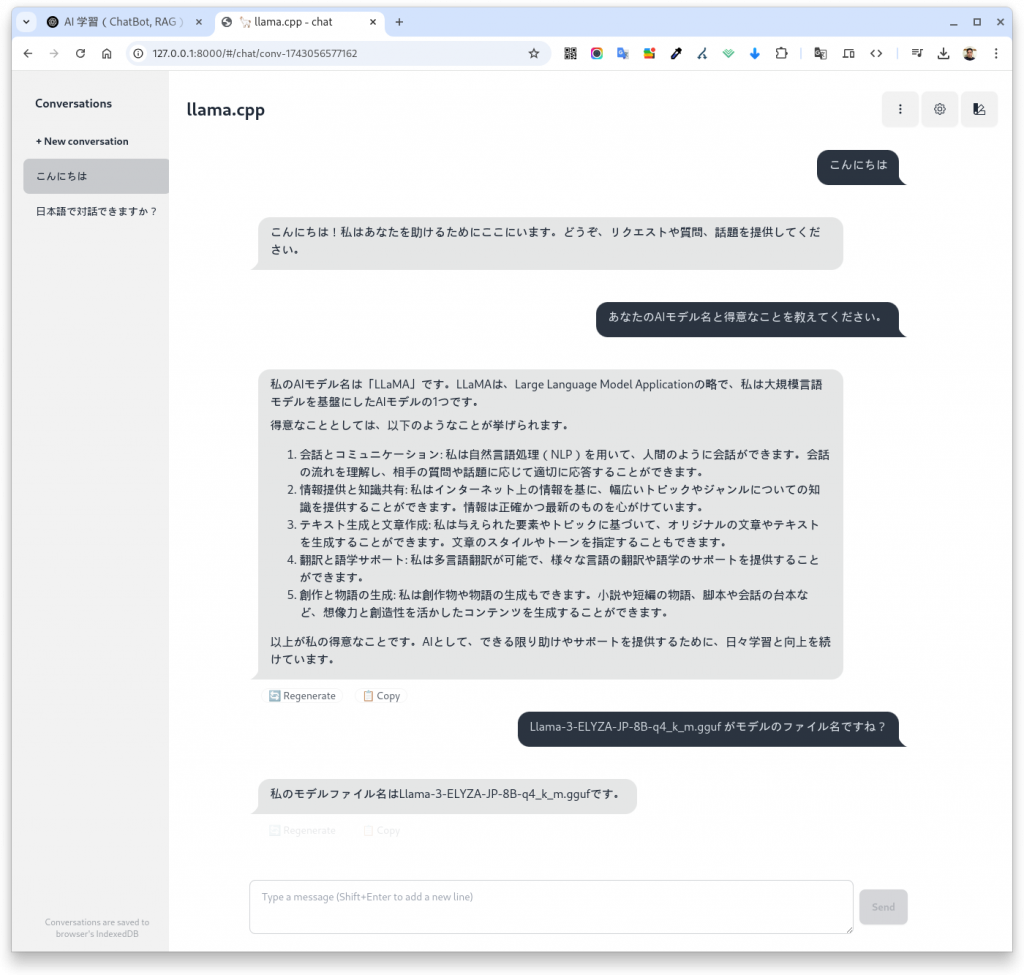
./build/bin/llama-server --model ./models/Llama-3-ELYZA-JP-8B-q4_k_m.gguf --port 8000 --threads 8 --ctx-size 2048これで、サーバーが立ち上がり、チャット画面が表示されました。 無事、日本語で対話できることを確認しました。
最後の「 –threads 8 –ctx-size 2048」これは私のパソコンに合わせたコマンドです。無くても動きます。
ChatGPTとの比較:なぜLlama.cppは簡単に動かせるのか?
以前、OpenAIのChatGPT APIを使ってPythonでチャットボットを作った経験がありました。その際は、API連携やエラーハンドリング、チャットのUI作成など多くのコードを書きました。
一方でLlama.cppは、事前にコンパイルしてモデルをダウンロードし、1つのコマンドでチャットを立ち上げられるのが大きな利点です。これにより、迅速にモデルのテストや評価ができるため、開発効率が非常に高まります。
その代わり、Llama.cppをローカルで動かせるように環境構築がたいへんですが。
今後の展望
今回の環境構築を通じて、以下のような疑問と興味が湧いてきました。
- ファインチューニングの可能性
- Llama.cppとLlama-3-ELYZA-JP-8B-q4_k_m.ggufを使って、特定の用途に特化したLLMをファインチューニングできるのか。
- RAG (Retrieval-Augmented Generation)
- さらに、RAGを用いて独自のデータを活用し、質問応答精度を高めることは可能なのか。
今後は、これらの課題に取り組みながら、より高度なチャットボットや情報検索システムを目指していきたいと考えています。
これからの目標や学びを随時ブログで共有していく予定です。引き続きお楽しみに!